Understanding the Kubernetes kube-api-server: A Deep Dive
--- kube-api-server ---


In the world of Kubernetes, the kube-apiserver plays a critical role as the frontend to the cluster’s shared state, allowing users and Kubernetes internal components to interact with one another. This blog aims to provide a detailed yet comprehensible explanation of what kube-apiserver is, its functions, architecture, and why it is crucial for Kubernetes operations.
What is kube-apiserver?
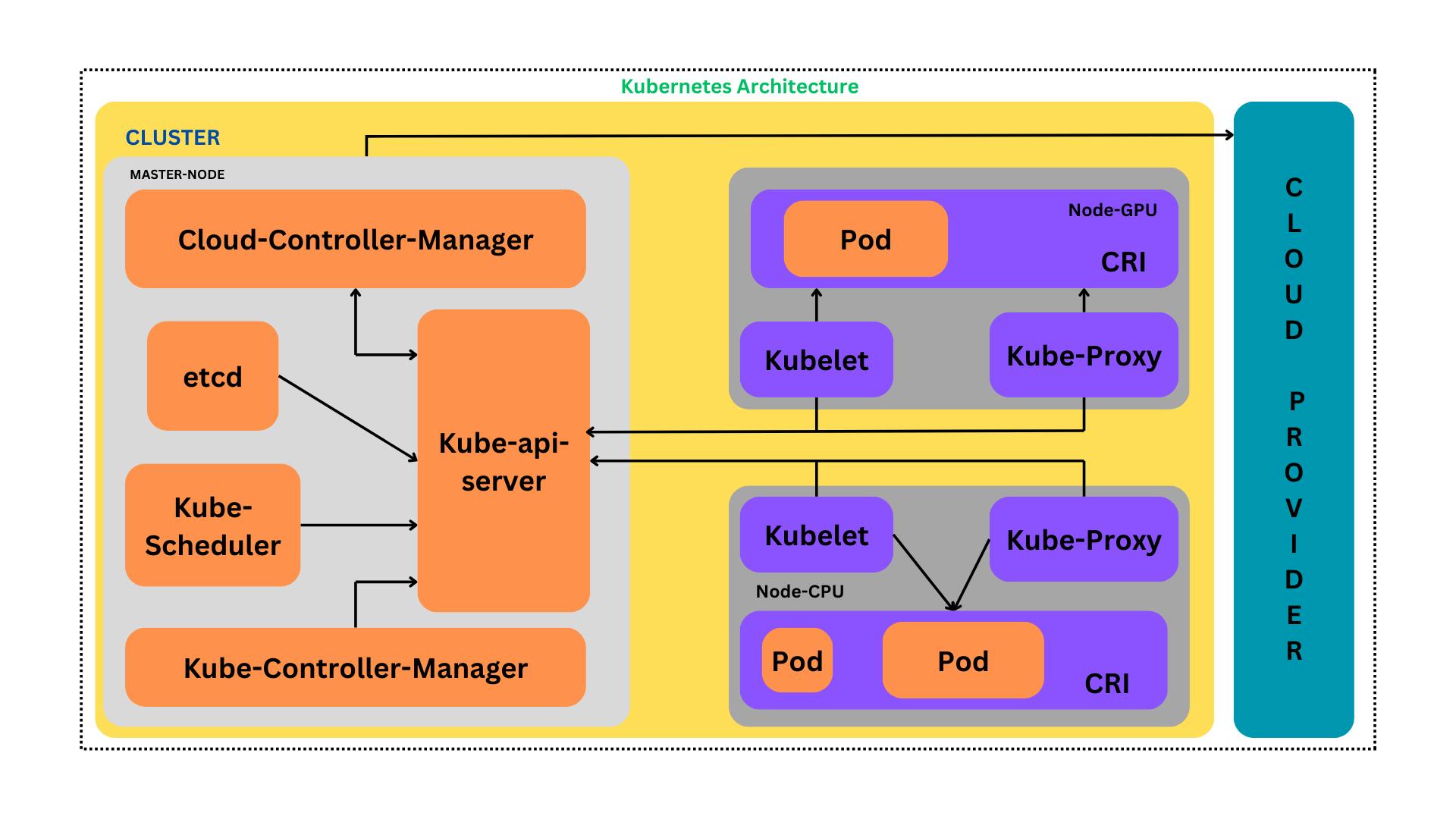
Kubernetes is a powerful system for managing containerized applications across a cluster of machines. It abstracts away the underlying hardware and exposes it as a single deployment platform. At the heart of this system is the kube-apiserver, which is the central management entity of Kubernetes.
The kube-apiserver is a component of the Kubernetes control plane that exposes the Kubernetes API. It is the service through which all internal system components and external user commands communicate with the cluster. Every operation on the cluster is driven through the API server, from starting up a new pod to scaling an entire deployment.
Key Responsibilities of kube-apiserver
The kube-apiserver performs several critical functions:
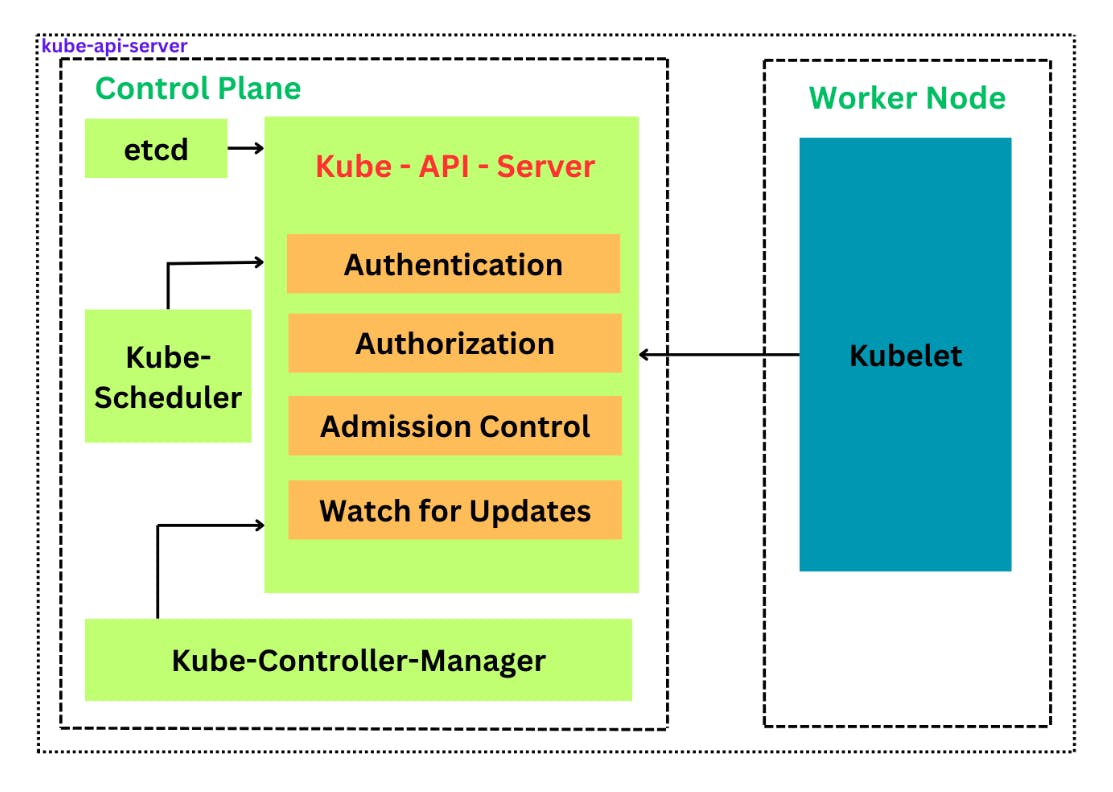
API Exposure: It exposes the Kubernetes API, which is both an internal and external-facing HTTP interface. Through this API, it handles and validates REST requests and updates state objects within the cluster’s etcd storage, ensuring that all components are consistently synchronized.
Authentication: It authenticates users interacting with the Kubernetes cluster, determining whether they have permissions to perform requested actions.
Authorization: Once a request is authenticated, kube-apiserver performs authorization to determine if the requester is allowed to perform the requested operation.
Admission Control: This is a critical security and governance tool. Before a request is allowed to proceed, kube-apiserver processes it through various admission control modules, which can modify or reject requests under certain conditions.
Regulatory Compliance: By logging every API request and its response, kube-apiserver allows auditing of all changes and interactions with the cluster, which is vital for compliance and security monitoring.
How kube-apiserver Works
The kube-apiserver operates as a collection of processes (possibly running on different machines) that communicate through the cluster’s network. Here’s a simplified workflow:
Receiving API Requests: Clients like kubectl or other administrative tools make HTTP/HTTPS requests to the kube-apiserver.
Authentication and Authorization: Each request is authenticated and authorized. Authentication can be handled via static tokens, certificates, or third-party authentication like OpenID Connect. Authorization can be managed through roles and policies defined in Kubernetes.
Admission Control: Before a request is executed, it passes through several admission controllers. These controllers can enforce security policies, limit resources, and ensure overall integrity of the cluster.
Watch for Updates: kube-apiserver also provides a mechanism to "watch" for changes to specific objects and return a stream of updates. This is crucial for controllers to maintain desired state, for dashboards to show up-to-date information, and for other clients that need to react to changes within the cluster in real time.
Data Storage: If a request alters the state of the cluster (like creating a pod or updating a service), kube-apiserver modifies the records in etcd, a highly-available key-value store used to store all data needed to run the cluster.
Architecture of kube-apiserver
The architecture of kube-apiserver is designed to be highly scalable and fault-tolerant. It can be deployed as a single instance but typically runs in multiple instances to distribute load and ensure high availability. Load balancers are used to distribute requests among multiple instances of kube-apiserver.
Scaling and Performance Optimization
Kubernetes allows for scaling kube-apiserver both vertically (adding more power to the existing machines) and horizontally (adding more machines). This flexibility helps manage larger clusters efficiently. Caching mechanisms and efficient API operation batching are crucial for optimizing the performance of kube-apiserver.
Why is kube-apiserver so critical?
Without kube-apiserver, the Kubernetes cluster would be unable to function. It acts as a gateway and a brain for the cluster, processing all administrative and operational tasks. It is essential for the correct functioning of the Kubernetes control plane and for ensuring that the state of the cluster matches the user's specifications at all times.
Conclusion
Understanding kube-apiserver is fundamental to mastering Kubernetes. It is not just the gateway through which all cluster operations flow but also a critical component ensuring the security, compliance, and efficient operation of your Kubernetes environment. As you dive deeper into Kubernetes, appreciating the nuances of kube-apiserver will greatly enhance your ability to deploy and manage robust, scalable applications.
Keep Exploring...